Llama 3이란?
Llama 3가 공개된지 몇주가 지났지만 드디어 소개드립니다. 그동안 정말 많이 Llama3 가지고 여러 테스트와 파인튜닝 작업을 진행하느라 좀 늦게 가져왔습니다. Llama 3은 현재까지 공개적으로 사용 가능한 가장 능력 있는 LLM(Large Language Model) 중 하나입니다. 이 모델은 현재 8B와 70B의 Base모델과 Instruct 모델이 각각 공개 되어있으며, 추후에 400B 크기의 모델도 공개 예정이라고 합니다. Llama3는 대체로 언어의 다양한 뉘앙스를 이해하며, 번역, 대화 생성 등의 작업에서 뛰어난 성능을 발휘합니다.
성능 향상
Llama 3은 llama2 이용해서 데이타셋 정제와 생성을 일부 이용해서 확장 가능성과 성능을 더욱 향상시켰습니다. 이제 다단계 작업을 효율적으로 처리할 수 있으며, 거짓 거부율을 낮추고 응답 정렬을 개선했습니다. 또한 모델 답변의 다양성을 높여 사용자에게 더욱 풍부한 경험을 제공합니다. Llama 3의 개발은 책임 있는 방향으로 이루어졌습니다. Responsible Use Guide(RUG)를 업데이트하고, Llama Guard 2와 같은 안전 도구를 사용하여 사용자 지정 콘텐츠의 안정성을 유지합니다. 입력과 출력을 철저하게 확인하고 필터링하여 사용자의 안전을 보장합니다.
Meta Llama 3 모델의 특징
이 모델은 다양한 특수 토큰을 활용합니다. 이러한 토큰은 모델의 작동 방식을 이해하는 데 도움이 됩니다.
Meta Llama 3 모델 토큰: 이 모델에서 사용되는 특수 토큰에 대한 설명이 있습니다. 예를 들면 <|begin_of_text|>, <|eot_id|>, <|start_header_id|>, <|end_header_id|> 등이 있습니다.
Meta Llama 3 모델 기본 형식: 이 모델을 사용하여 단일 메시지 또는 다중 턴 대화를 생성하는 방법에 대한 코드 예제가 있습니다.
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
{{ user_message }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>Meta Llama 3 모델 채팅: 이 모델을 사용하여 채팅을 생성하는 방법에 대한 코드 예제가 있습니다.
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{{ system_prompt }}<|eot_id|><|start_header_id|>user<|end_header_id|>
{{ user_message }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>!pip install -U transformers accelerate bitsandbytes
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
model_id
)
model = AutoModelForCausalLM.from_pretrained(model_id,
return_dict=True,
torch_dtype='auto',
device_map='auto',
do_sample=True,
load_in_4bit=True,
)
chat = [
{ "role": "system", "content": " You are an artificial intelligence assistant that answers in Korean." },
{ "role": "user", "content": f"{text}" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
temperature=0.6,
top_p=0.9,
max_new_tokens=256,
eos_token_id=[
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
],
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1) :], skip_special_tokens=True)
print(output)하루 우라라의 ① 효과는, 이하의 어느 효과를 포함하는 마법/함정/몬스터의 효과가 발동했을 때, 이 카드를 패에서 버리고 발동할 수 있습니다. 개기일식의 서의 ① 효과는 필드의 앞면 표시 몬스터를 전부 뒷면 수비 표시로 하는 효과입니다.
따라서, 하루 우라라의 ① 효과는 개기일식의 서의 ① 효과를 포함하는 효과입니다. 따라서, 하루 우라라를 발동하여 상대의 효과를 무효화할 수 있습니다! 🎉이번 라마3는 라마2와 달리 한국어도 잘 사용하고, 특징이라면 이모티콘을 기본적으로 자주 사용하는 것을 볼 수있습니다.
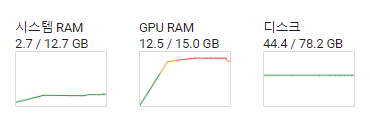
콜랩에서도 8B정도의 크기는 무사히 돌아가고, 양자화 하기전과 양자화 하기전의 8B의 GPU 사용량입니다. 양자화 전에는 12.5GB 사용하고 bnb로 4bit 로드 했을 때 6.3GB정도 사용하는 것을 볼 수 있습니다.

'코딩 > 모델 리뷰' 카테고리의 다른 글
| gemma3 vllm에서 dtype bfloat16과 float16 빈칸 문제 (0) | 2025.04.03 |
|---|---|
| 멀티모달 리뷰 qresearch의 llama3-vision-alpha 콜랩 구동 (0) | 2024.05.09 |
| 모델 리뷰 믹스트랄 8x22B 4bit 구동 해보자 (0) | 2024.04.16 |
| 모델 리뷰 OLMo Bitnet 1B을 colab에서 실행해보자 (0) | 2024.04.03 |
| 모델 리뷰 anthropic의 Claude 3 사용 및 API 사용법 (0) | 2024.03.06 |


