양자화
- LLM 모델을 양자화 하기
- 양자화 모델 실행하기
- 양자화 모델 파인 튜닝하기
양자화 모델의 필요성
양자화 하지 않는 라마2의 경우 필요한 사양
훈련 기준
7B 모델의 경우, "GPU - 1x Nvidia A10G 12gb"를 권장.
13B 모델의 경우, "GPU - 1x Nvidia A100 40gb"을 권장.
70B 모델의 경우, "GPU - 8x Nvidia A100 40gb"을 권장. 훈련시 대략 최소 320GB
양자화 개념요약
양자화
성능의 정확도 손실에 미치지 않는 범위에서 float32에서 4bit,8bit와 같이 저밀도가 낮은 데이터 타입으로 표현해서 효율적 계산을 수행하도록 하는 방법 주로, 입력을 정량화 상수로 스케일링 하여 입력을 정규화 하는 것으로, 학습이 완료된 가중치에 float 32에서 가중치 min값과 max값이 생기는데 int에 매칭 시켜주므로써 메모리 사용량을 획기적으로 줄여주는 방법
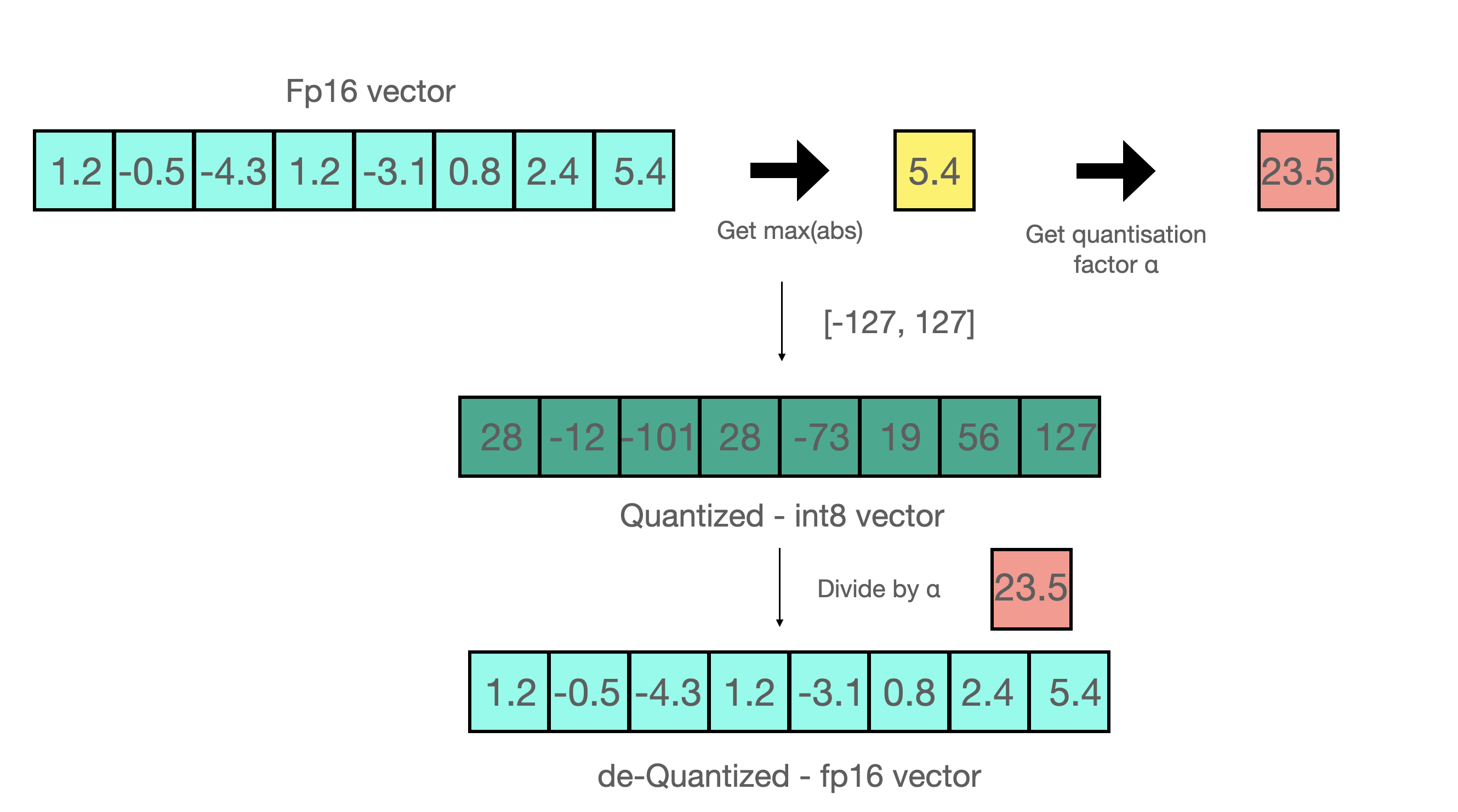
동적 양자화
추론 즉시 양자화가 즉석해서 일어남,부동 소수점과 정수 간의 변환시 병목현상이 일어난다.
정적 양자화
추론전에 샘플 데이터를 분석하여 양자화 체계를 사용하여 양자화하는 방법, 성능 저하 가능성이 낮지만 샘플데이터의 영향을 받는다.
양자화 인식훈련(QAT): 훈련 또는 추가 미세 조정 전에 정량화가 수행됩니다.
훈련 후 정량화(PTQ): 보정 데이터 세트와 몇 시간의 계산 등 적당한 리소스를 사용하여 사전 학습된 모델을 정량화합니다.
GPTQ
GPTQ는 전체 모델 훈련이나 미세 조정 비용이 매우 많이 드는 대규모 모델에 특히 유용합니다. GPTQ는 PTQ 범주에 속하며, 원샷 가중치 정량화 접근법을 사용합니다. GPTQ는 샘플데이터로부터 2차 정보인 헤시안 행렬을 활용과 계층별 양자화와 사용합니다.
계층별 양자화를 통해 각 계층(layer)의 "원래 출력"과 "양자화된 출력" 간의 "제곱 오차를 최소화"함으로써 양자화를 수행합니다. 2차 정보인 헤시안 행렬은 함수의 기울기와 곡률을 모두 나타내는 2차 도함수로 각 가중치의 양자화 오차를 계산하고, 이를 최소화하여 제곱 유클리드 노름을 최소화하는 방식으로 가중치를 정량화합니다.
GPTQ의 정확도는 그룹화를 통해 개선될 수 있으며, 여기서 그룹사이즈는 압축 당시에 묶을(그룹핑될) 가중치의 사이즈입니다. 그룹화 크기가 작을 수록 정확하지만, 비용과 trade off 때문에 대체로 128을 사용합니다.
수식)
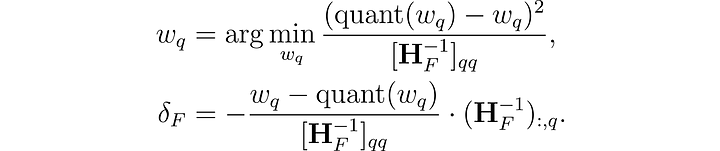
w가 각층의 weight이고, 제곱의 오차를 최소화하고, H를 (...)해서 양자화를 한다.
H: 헤시안 행렬
AutoGPTQ
https://github.com/qwopqwop200/GPTQ-for-LLaMa
https://github.com/PanQiWei/AutoGPTQ
양자화 시키기
GPTQ 양자화는 현재 텍스트 모델에서만 작동합니다. 또한 양자화 프로세스는 하드웨어에 따라 많은 시간이 소요될 수 있습니다
(175B 모델 = NVIDIA A100 사용 시 4 gpu 시간). 정량화하려는 모델의 GPTQ 정량화 버전이 아직 없는 경우 허깅 페이스 허브에서 확인하시기 바랍니다.
from transformers import AutoModelForCausalLM, AutoTokenizer
from optimum.gptq import GPTQQuantizer, load_quantized_model
import torch
model_name = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16)
model
OPTForCausalLM(
(model): OPTModel(
(decoder): OPTDecoder(
(embed_tokens): Embedding(50272, 768, padding_idx=1)
(embed_positions): OPTLearnedPositionalEmbedding(2050, 768)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(layers): ModuleList(
(0-11): 12 x OPTDecoderLayer(
(self_attn): OPTAttention(
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(activation_fn): ReLU()
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
)
)
(lm_head): Linear(in_features=768, out_features=50272, bias=False)
)quantizer = GPTQQuantizer(bits=4, dataset="c4", block_name_to_quantize = "model.decoder.layers", model_seqlen = 2048)
quantized_model = quantizer.quantize_model(model, tokenizer) # k,v,q,o,fc1,fc2 # 4분정도
quantized_model
OPTForCausalLM(
(model): OPTModel(
(decoder): OPTDecoder(
(embed_tokens): Embedding(50272, 768, padding_idx=1)
(embed_positions): OPTLearnedPositionalEmbedding(2050, 768)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(layers): ModuleList(
(0-11): 12 x OPTDecoderLayer(
(self_attn): OPTAttention(
(k_proj): QuantLinear()
(out_proj): QuantLinear()
(q_proj): QuantLinear()
(v_proj): QuantLinear()
)
(activation_fn): ReLU()
(self_attn_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(fc1): QuantLinear()
(fc2): QuantLinear()
)
)
)
)
(lm_head): Linear(in_features=768, out_features=50272, bias=False)
)
quant_model.save_pretrained("opt-125m-gptq")
tokenizer.save_pretrained("opt-125m-gptq")임의의 데이터로 양자화
from transformers import AutoModelForCausalLM, GPTQConfig, AutoTokenizer
quantization_config = GPTQConfig(
bits=4,
group_size=128,
desc_act=False,
dataset=["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
quant_model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quantization_config, torch_dtype=torch.float16, device_map="auto")빠른 추론을위한 Exllama 커널
4 비트 모델의 경우 빠른 추론 속도를 위해 exllama 커널을 사용할 수 있습니다. 기본적으로 활성화됩니다. 통과하여 그 동작을 변경할 수 있습니다.
gptq_config = GPTQConfig(bits=4, disable_exllama=False)'코딩 > LLM' 카테고리의 다른 글
| LLaVA-1.5 이미지 텍스트 멀티모달 (1) | 2023.10.10 |
|---|---|
| 양자화 모델 실행과 LoRA 파인 튜닝 (1) | 2023.10.08 |
| LLM 기반의 서비스 만들 때 (1) | 2023.10.06 |
| VLLM 소개 (0) | 2023.08.29 |
| llama2를 context 8k까지 확장하는 방법 RoPE, exllama (0) | 2023.08.24 |


