https://hyeong9647.tistory.com/9
이어서
양자화된 모델 불러오기
양자화된 모델 불러오는 과정은 생각보다 간단하다.
다 AutoGPTQ가 해주기 때문이다.
import torch
from transformers import AutoTokenizer
from transformers import AutoModelForCausalLM, TextStreamer
model_name = "TheBloke/Llama-2-7b-Chat-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto") # quantize_config.json이 있으면 따로 해줄필요 없다.
streamer = TextStreamer(tokenizer)
model.config.quantization_config.to_dict()
input_ids = tokenizer("Be yourself;", max_length=128, truncation=True, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, streamer=streamer, temperature=0)
decode_output = tokenizer.decode(output[0])
decode_output
파인 튜닝 LoRA
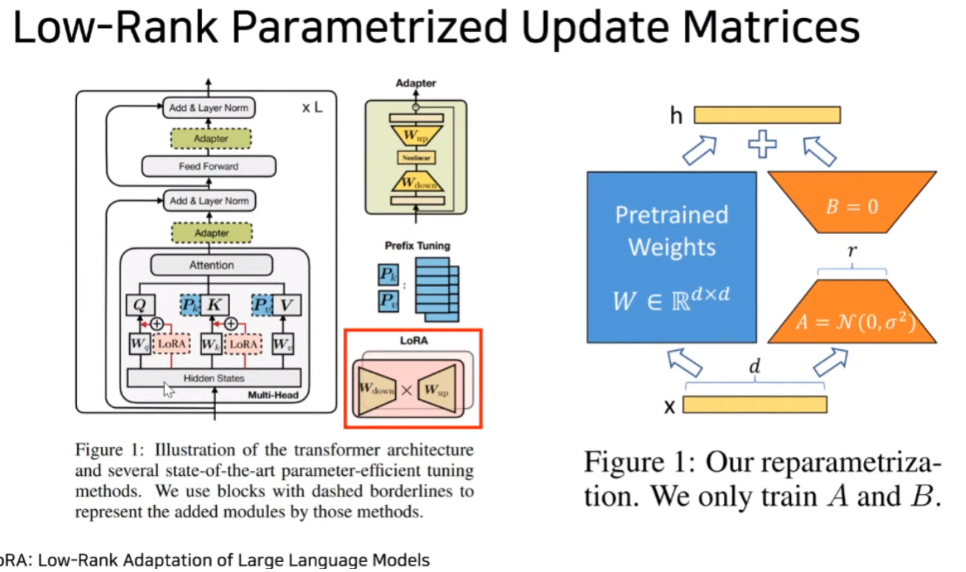
경사 하강법의 의한 가중치 업데이트 방식을 모방하므로서 LoRA가 일종의 가중치 업데이트가 된다.
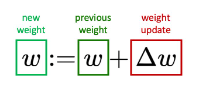
W0x + delta Wx에 대한 보강 설명 링크.
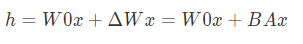
Full Rank Parameter VS LoRA Parameter
(4096*4096) VS (4096 * 8) + (8 * 4096) (r=8)
= 16,777,216 VS 65,536
마이크로소프트에서는 LLM을 파인튜닝하기 위해 개발한 방법은 기존 모델의 가중치를 동결한 후, 학습 가능한 rank decomposition matrices(순위 분해 행렬)를 트랜스포머 아키텍처의 각 계층에 주입하는 방식입니다.
이는 GPU 메모리 요구량과 훈련 가능한 파라미터 수를 획기적으로 줄일 수 있는 장점이 있습니다.
Pretrained Weights는 동결시키고 A와 B만 학습합니다. 여러 항목 중에서 LoRA가 가장 일정하게 좋은 정확도를 유지하는 것을 알 수 있습니다.
따라서, 사전 학습된 모델을 그대로 공유하면서 작은 LoRA 모듈을 여러 개 만들 수 있습니다. 모델을 공유하면서 새로 학습시키는 부분(A, B)만 쉽게 바꿔 끼울 수 있습니다.
간단한 선형 설계 덕분에 훈련 가능한 행렬을 배포할 때, 고정 가중치와 병합할 수 있으므로 추론 지연 시간이 발생하지 않습니다.
트랜스포머 층 사이에 추가되기 때문에, 연산에 필요한 메모리 사용량이 시퀀셜하게 증가되는 단점이 존재합니다.
LoRA는 모든 dense layer에 적용 가능하며 Neural Network는 많은 dense layer를 포함하고 있으며 Matrix multiplication을 수행합니다. 이 matrices의 weight는 일반적으로 full-rank입니다.
가중치를 업데이트하려면 gradient descent를 사용하여 얼마나 많은 가중치를 업데이트할 지를 결정하는 과정이 필요합니다.
이 중 nm linear로 된 행렬들에 대한 업데이트를 low-rank decomposition을 통해 업데이트 된 가중치로 근사하여 원래 weight에 더하는 개념입니다.
W0x에 대해 B,A의 행렬의 곱을 가중치로서 더해줬기 때문에 일종의 업데이트 해주는 형태가 되었다고 볼 수 있다.
from peft import prepare_model_for_kbit_training
from transformers import AutoModelForCausalLM, GPTQConfig, AutoTokenizer
model_id = "TheBloke/Llama-2-7b-Chat-GPTQ"
quantization_config_loading = GPTQConfig(bits=4, disable_exllama=False)
model = AutoModelForCausalLM.from_pretrained(model_id,quantization_config=quantization_config_loading, device_map="auto")
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=8, # 업데이트 행렬의 순위로, 정수로 표현됩니다. 낮은 순위는 더 적은 학습 가능한 파라미터를 가진 작은 업데이트 행렬을 생성합니다. A = 4096 * r, B= r*4096
lora_alpha=32, # LoRA 스케일링 팩터입니다. # 모름
target_modules=["k_proj","o_proj","q_proj","v_proj"], #의 모든 레이어가 변환됩니다.
lora_dropout=0.05, # 드롭 아웃
bias="none", # 편향(bias) 파라미터를 학습시킬지 지정합니다. 'none', 'all', 'lora_only' 중 하나일 수 있습니다.
task_type="CAUSAL_LM" # task 타입
)
model = get_peft_model(model, config)
model.print_trainable_parameters()
#데이터셋 로드
from datasets import load_dataset
tokenizer = AutoTokenizer.from_pretrained(model_id)
data = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
data['train'][0]from transformers import Trainer, TrainingArguments, DataCollatorForLanguageModeling
# needed for llama 2 tokenizer
tokenizer.pad_token = tokenizer.eos_token
trainer = Trainer(
model=model,
train_dataset=data["train"],
args=TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=2,
max_steps=20,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="./output_dir",
optim="adamw_hf"
),
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
trainer.train()
trainer.save_model("./save_lora_dir")
# 일부러 비교를 위해 훈련을 많이 시켜본다LoRA Load
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, GPTQConfig, AutoTokenizer
config = PeftConfig.from_pretrained('./save_lora_dir')
model_id = "TheBloke/Llama-2-7b-Chat-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config_loading = GPTQConfig(bits=4, disable_exllama=True)
model = AutoModelForCausalLM.from_pretrained(model_id,quantization_config=quantization_config_loading, device_map="auto")
model = PeftModel.from_pretrained(model, './save_lora_dir')
model이렇게 끝!
'코딩 > LLM' 카테고리의 다른 글
| RLHF 인간 피드백 강화학습 코드분석 (chatllama, stackllama) (1) | 2023.10.24 |
|---|---|
| LLaVA-1.5 이미지 텍스트 멀티모달 (1) | 2023.10.10 |
| AutoGPTQ를 이용한 양자화 하는 방법 (1) | 2023.10.07 |
| LLM 기반의 서비스 만들 때 (1) | 2023.10.06 |
| VLLM 소개 (0) | 2023.08.29 |



