728x90
300x250
https://github.com/turboderp/exllamav2/blob/master/doc/convert.md
#데이터셋 만들기 parquet형식을 만들어야된다.
# 한글모델 양자화를 위해 코알파카셋을 사용한다.
from datasets import load_dataset
ds = load_dataset("beomi/KoAlpaca-v1.1a", split="train")
ds_list = []
for i in range(len(ds)):
ds_list.append(f"### User:\n{ds[i]['instruction']}\n\n### Assistant:\n{ds[i]['output']}")
df = pd.DataFrame({'instruction':ds_list})
df.to_parquet("./ds.parquet")
# safetensors 형식으로 저장해줘야된다.
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
)
model.save_pretrained(f"{model_name_or_path}/quant_model/",max_shard_size="40GB", safe_serialization=True)# 리눅스 명령어
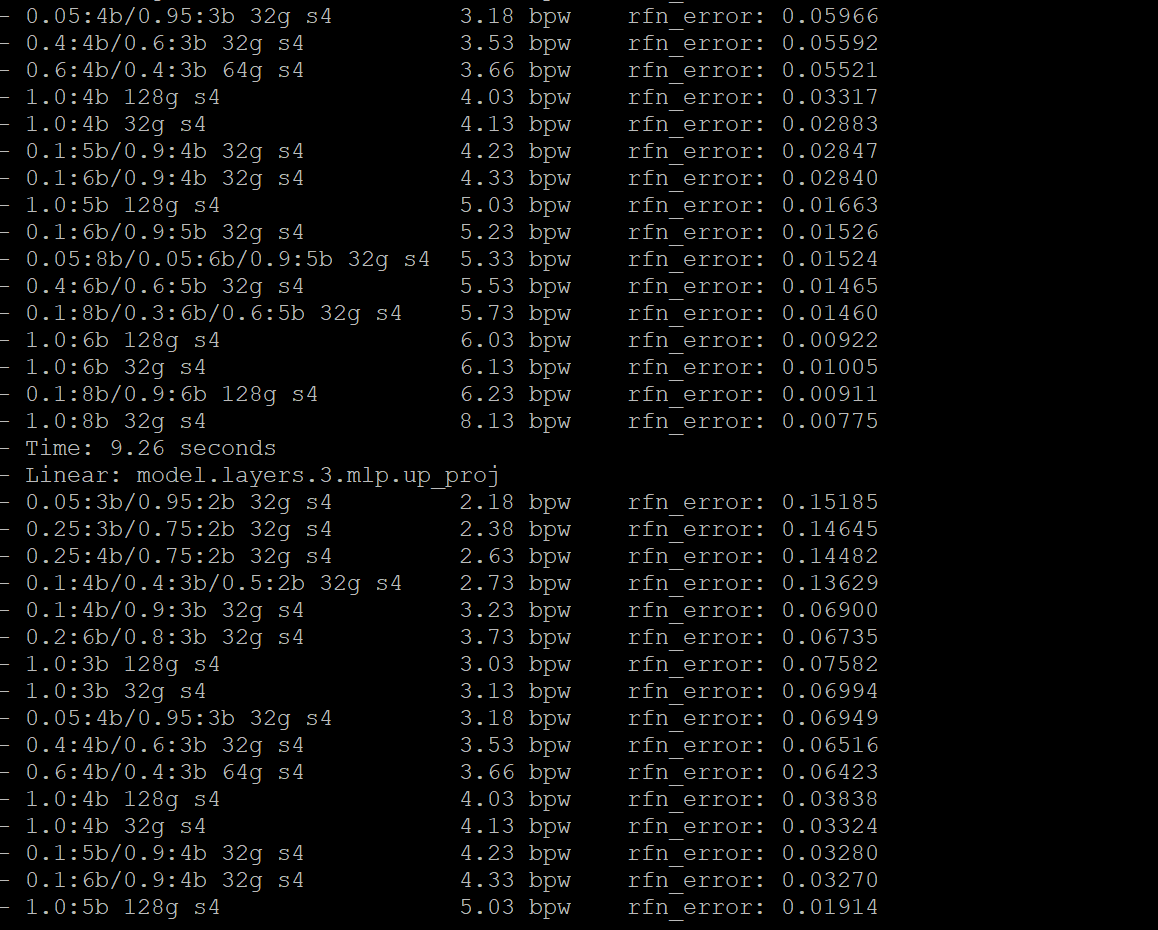
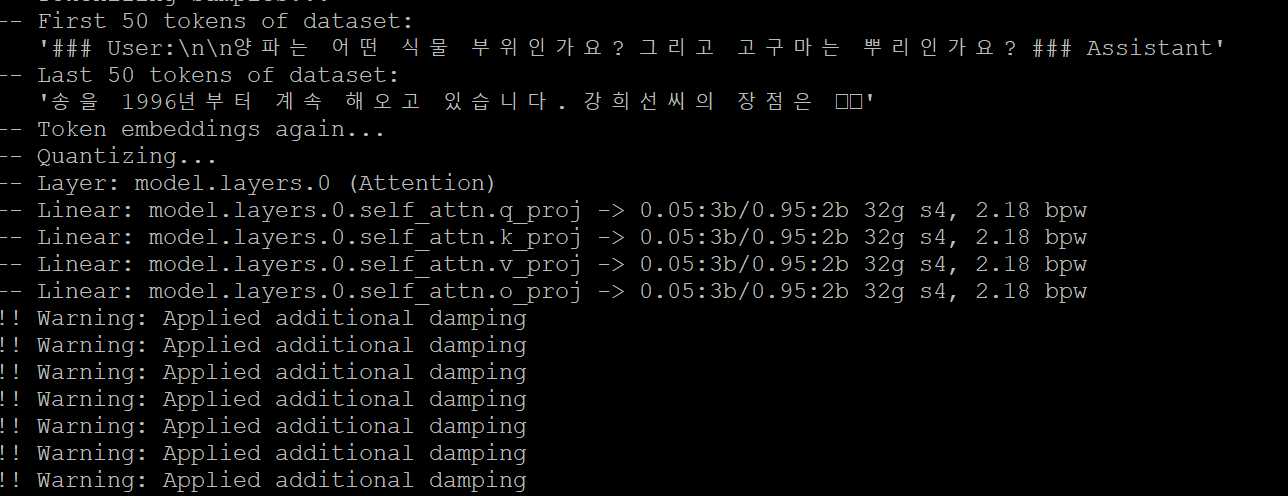
python convert.py -i llama2-ko-en-platypus-13B -o llama2-ko-en-13B-temp -cf llama2-ko-en-4.0bpw-h8-exl2 -c cal_dataset.parquet -l 4096 -b 4 -hb 8 -ss 4096데이터셋은 준비했고, 모델도 형식에 맞게 변환했고
리눅스에서 명령어로 exl2를 변환해주는 코드를 작성해주면된다.
보면서 따라 했는데도 힘들구먼
결과가 잘나올려나
텍스트가 깨져서 실패함 ㅠ 다시 시도
728x90
300x250
'코딩 > 프로젝트' 카테고리의 다른 글
| lora finetuning 후 EOS token이 안나오는 문제 (0) | 2023.10.28 |
|---|---|
| llama2에 remon 데이터로 LoRA 학습기 (0) | 2023.10.25 |
| AutoGPTQ로 양자화 직접 해보기 (0) | 2023.10.23 |
| nllb200을 이용한 다국어 번역 (0) | 2023.08.17 |
| Transformers를 generator로 만드는 방법 (0) | 2023.08.16 |
