간단히 llama2를 통해 remon데이터를 학습시켜서 AI 캐릭터을 만드는 짓을 하겠다 remon data는 허깅 페이스에서 쉽게 구할 수 있음 nsfw가 없는 클린한 데이터를 사용합니다.
https://huggingface.co/datasets/junelee/remon_without_nsfw
junelee/remon_without_nsfw · Datasets at Hugging Face
[ { "from": "human", "value": "Hi Lemon, how was your day today?" }, { "from": "gpt", "value": "Hi there! My day was wonderful, as always, since I spent it with you. How about you, how was your day?" }, { "from": "human", "value": "It was good, thanks for
huggingface.co
로라 학습 하는 방법은 지난번에도 올려둔게 있지만 이번에도 할 거 없으니 같이 보면서 하겠습니다.
사용하실 모델을 로드를 합니다.
로드가 완료되면 peft를 통해 LoRA의 형태로 변환해야되는데 저는 지금 bitsandbytes의 8bit양자화를 사용해 할 것이기 때문에 kbit_training을 선언해주는 작업을 합니다. 그리고 미리 model을 봐서 어떤 레이어들에 LoRA를 붙힐지 target_modules에 입력해주면 됩니다.
하다보니깐 r=8일때는 생각보다 결과가 않좋아서 16으로 변경해주었습니다.
import torch
from transformers import AutoModelForCausalLM, GPTQConfig, AutoTokenizer
model_id =
model = AutoModelForCausalLM.from_pretrained(model_id,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto',
load_in_8bit=True
)
modelfrom peft import LoraConfig, get_peft_model
from peft import prepare_model_for_kbit_training
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
config = LoraConfig(
r=16, # 업데이트 행렬의 순위로, 정수로 표현됩니다. 낮은 순위는 더 적은 학습 가능한 파라미터를 가진 작은 업데이트 행렬을 생성합니다. A = 4096 * r, B= r*4096
lora_alpha=32, # LoRA 스케일링 팩터입니다. # 모름
target_modules=["k_proj","o_proj","q_proj","v_proj"], #의 모든 레이어가 변환됩니다.
lora_dropout=0.05, # 드롭 아웃
bias="none", # 편향(bias) 파라미터를 학습시킬지 지정합니다. 'none', 'all', 'lora_only' 중 하나일 수 있습니다.
task_type="CAUSAL_LM" # task 타입
)
model = get_peft_model(model, config)
model.print_trainable_parameters()
훈련에 사용될 파라미터의 개수는 0.24%만 업데이트가 되는 것을 확인 할 수 있었습니다.
훈련에 사용될 데이터셋을 전처리하는 과정이 필요한데요 여기서는 "### Instruction:", "### Response:"을 사용했습니다. 그리고 Response: 뒤에는 EOS Token이 될 </s>를 넣어 주었습니다.
import json
import torch
from transformers import AutoTokenizer
from torch.utils.data import Dataset
# JSON 데이터 로드
with open('/kaggle/input/reomon-v01/remon_01v_without_19.json', 'r', encoding='utf-8') as file:
data = json.load(file)
# 모델 토크나이저 로드
tokenizer = AutoTokenizer.from_pretrained("beomi/llama-2-ko-7b") # 모델 이름은 사용하려는 모델에 따라 지정
# 최대 시퀀스 길이 설정
max_sequence_length = 4096
def prompt_chat_completion(dialog, system_token="### System:", user_token="### Instruction:", assistant_token="### Response:", start_token="", end_token=""):
role_dict = {"system":system_token, "human":user_token, "gpt":assistant_token}
dialog_text = [f"""{role_dict[prompt['from']]}
{start_token}{prompt['value'].strip()}{end_token}
{role_dict[answer['from']]}
{start_token}{(answer['value']).strip()}{end_token}</s>"""
for prompt, answer in zip(dialog[::2], dialog[1::2])]
dialog_tokens = ''.join(dialog_text).replace('\n\n</s>','</s>')
return f'<s>{dialog_tokens}'
split_data= []
for i in range(len(data)):
split_data.append(prompt_chat_completion(data[i]['conversations']))
# CustomDataset 정의
class CustomDataset(Dataset):
def __init__(self, data, tokenizer, max_sequence_length):
self.data = data
self.tokenizer = tokenizer
self.max_sequence_length = max_sequence_length
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
conversation = self.data[idx]
# 요 부분을 바꾸자
# prompt_templete = f"""<s>### Instruction:\n{conversation[0]['value']}\n\n### Response:\n{conversation[1]['value']}</s>"""
prompt_templete = conversation
# 텍스트를 토큰화하고 인코딩
encoding = self.tokenizer(
prompt_templete,
truncation=True,
max_length=self.max_sequence_length,
return_tensors='pt'
)
input_ids = encoding['input_ids'].squeeze()
attention_mask = encoding['attention_mask'].squeeze()
return {
'input_ids': input_ids,
'attention_mask': attention_mask
}
custom_dataset = CustomDataset(split_data, tokenizer, max_sequence_length)이번 학습에서는 8bit 학습이기 때문에 옵티마이저도 adamw_8bit을 사용합니다.
차이는 없는 거같지만요
from transformers import Trainer, TrainingArguments, DataCollatorForLanguageModeling
# needed for llama 2 tokenizer
trainer = Trainer(
model=model,
train_dataset=custom_dataset,
args=TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=2,
max_steps=20,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="./output_dir",
optim='adamw_8bit'
),
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
trainer.train()
trainer.save_model("./save_lora_dir")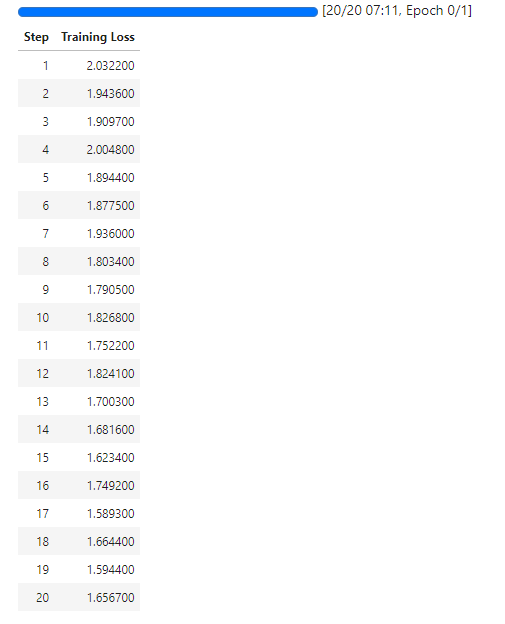
from transformers import TextStreamer
p = "뭐 하고 싶어?"
input_ids = tokenizer(f"### Instruction:\n{p}\n\n### Response:", max_length=128, truncation=True, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids,
streamer=TextStreamer(tokenizer),
stopping_criteria=early_stopping_list,
temperature=0.7,
repetition_penalty=1.5,
max_new_tokens=128,
)
output
완성! 이지만 계속 생성되서 stopping_criteria_list를 만들어줬어야만 했다 뭐가 문제일까나 ㅋㅋㅋㅋ
'코딩 > 프로젝트' 카테고리의 다른 글
| 깃허브 프로젝트 Langchain Prompt Ranking 만들었습니다. (0) | 2024.03.12 |
|---|---|
| lora finetuning 후 EOS token이 안나오는 문제 (0) | 2023.10.28 |
| AutoGPTQ로 양자화 직접 해보기 (0) | 2023.10.23 |
| exllamav2로 exl2형식으로 양자화하기 (1) | 2023.10.20 |
| nllb200을 이용한 다국어 번역 (0) | 2023.08.17 |


