LLaMA Factory는 대규모 언어 모델(Large Language Models, LLMs)을 손쉽게 파인 튜닝할 수 있는 프레임워크로 소개됩니다. 이것은 기술적인 이해가 있는 사람이든 없든, 누구에게나 적합합니다. 💡
이 튜토리얼은 어느 정도의 컴퓨팅 파워만 있다면 누구나 LLM 파인 튜닝에 참여할 수 있다는 점을 강조합니다. 💻
이 프레임워크는 다양한 기법인 PPO, DPO, SFT, 리워드 모델링 등을 지원하며, LoRA와 QLoRA 같은 다양한 훈련 방법론도 함께 제공합니다. 📚
LLaMA Factory의 사용 단계를 설명하는 튜토리얼에는 설치, 데이터셋 준비, 모델 선택, 파인 튜닝, 평가, 그리고 훈련된 모델과의 상호작용을 위한 대화 인터페이스 등이 포함됩니다. 🚀🎨📊
라마 팩토리 설치
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
conda create -n llama_factory python=3.10
conda activate llama_factory
pip install -r requirements.txt
pip install bitsandbytes>=0.39.0사용 방법
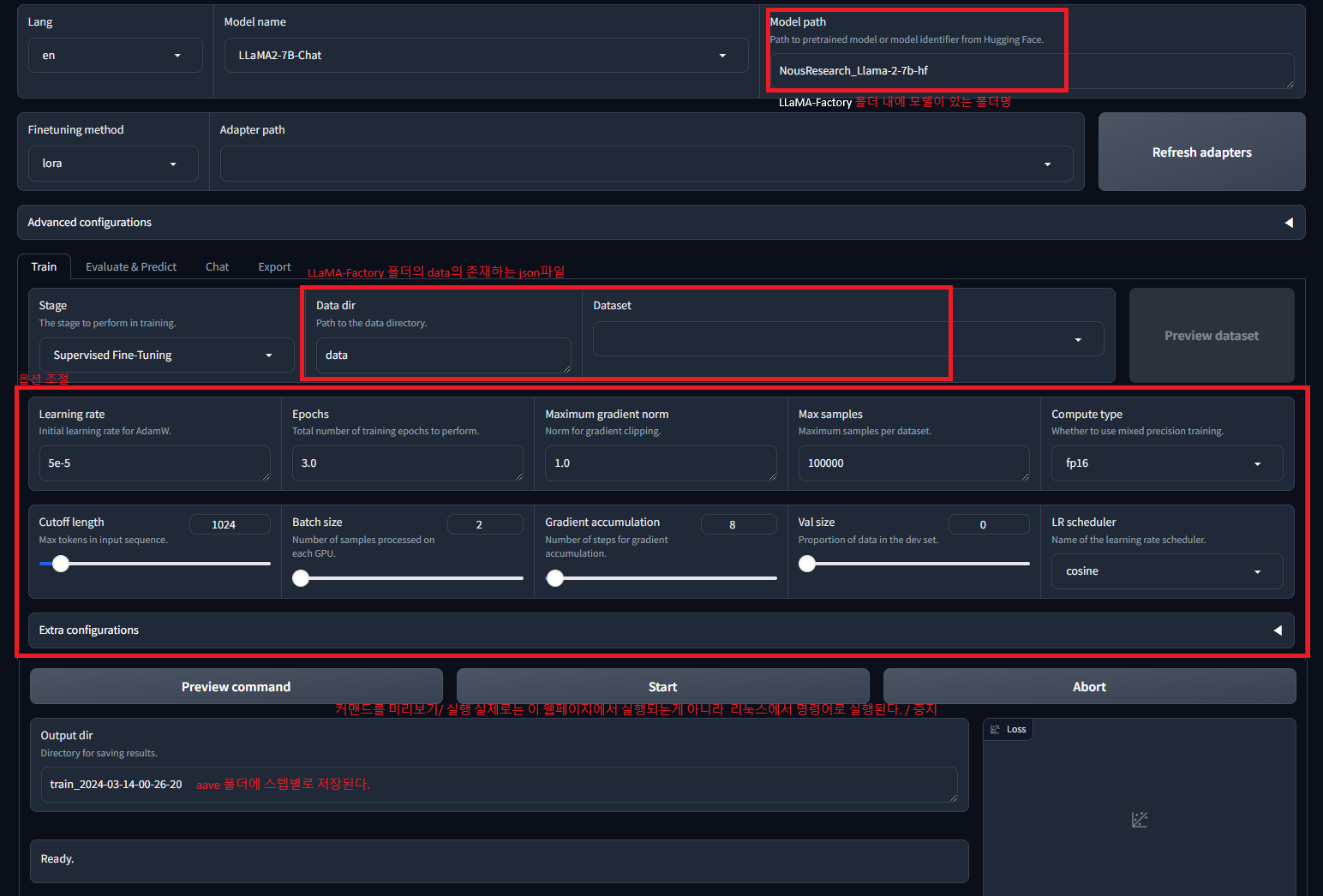
🚀 LLaMA-Factory: 파인 튜닝
라마 팩토리를 설치한 디렉토리에서 `python src/train_web.py`를 실행하면 파이썬으로 웹 UI를 간편하게 활성화할 수 있습니다. 이 웹 UI를 통해 사용자는 자신이 튜닝하고 싶은 모델과 옵션을 선택하여 명령어를 미리 확인하고, 훈련을 시작할 수 있습니다. 모델 이름은 튜닝하고자 하는 모델의 기본 모델에 맞게 설정하면 됩니다. 실제로 훈련할 모델은 `model_path`에 해당하는 위치에 넣어주시면 됩니다.
데이터를 불러오는 것 역시 간단합니다. Data dir에는 원하는 파일을 JSON 형식으로 제공하면 됩니다. 각 JSON 객체에는 "instruction", "input", "output", "history"와 같은 네 개의 필드가 있습니다. 그 중 "input"과 "history"는 모두 비워 둬도 됩니다.
훈련 데이터만 준비되면 LLaMA-Factory를 통해 쉽게 파인 튜닝이 가능합니다. 🎯
1. 모델 선택 및 설정: 사용자는 웹 UI를 통해 튜닝하고자 하는 모델을 선택하고 옵션을 조정할 수 있습니다.
2. 데이터 불러오기: JSON 형식으로 제공된 데이터를 바탕으로 모델을 훈련할 수 있습니다.
3. 파인 튜닝: LLaMA-Factory를 활용하여 모델의 성능을 미세 조정할 수 있습니다.
이처럼 LLaMA-Factory를 활용하면 파인 튜닝이 더욱 효율적으로 가능해집니다.🔍✨
자료 출처:
GitHub - hiyouga/LLaMA-Factory: Unify Efficient Fine-tuning of 100+ LLMs
Unify Efficient Fine-tuning of 100+ LLMs. Contribute to hiyouga/LLaMA-Factory development by creating an account on GitHub.
github.com
How to fine-tune Mixtral-8x7B-Instruct on your own data?
It takes just a few minutes over three steps:
blog.devgenius.io
How to format your own data for fine-tuning Mixtral-8x7B-Instruct?
This article shows a simple tool to convert Spreadsheets data into a json format for fine-tuning LLMs such as Mixtral-8x7B-Instruct.
blog.devgenius.io
'코딩 > 프로젝트' 카테고리의 다른 글
| 깃허브 프로젝트 Langchain Prompt Ranking 만들었습니다. (0) | 2024.03.12 |
|---|---|
| lora finetuning 후 EOS token이 안나오는 문제 (0) | 2023.10.28 |
| llama2에 remon 데이터로 LoRA 학습기 (0) | 2023.10.25 |
| AutoGPTQ로 양자화 직접 해보기 (0) | 2023.10.23 |
| exllamav2로 exl2형식으로 양자화하기 (1) | 2023.10.20 |


