
정의
- 사람의 피드백을 통해 파인튜닝함으로써 LM을 사용자 의도에 맞게 조정하는 방법이다. InstructGPT, ChatGPT 등에 사용되었다.
- 사람이 직접 평가한 결과, 1.3B의 파라미터를 가진 InstructGPT 모델이 GPT3-175B 모델보다 선호도가 높았다
- 퍼블릭 NLP 데이터 셋에서 성능 저하를 최소화하면서 진실성이 개선되고, 독성 출력 생성이 줄어들었지만 편향은 줄어들지 않았다
- InstructGPT는 단순한 실수를 하지만, 사람의 피드백을 통한 파인튜닝이 언어 모델을 사람의 의도에 맞게 조정하는 데 있어 유망한 방향임을 보여주었다.
절차
아래 그림은 RLHF의 절차를 보여준다. 지도 파인튜닝, 보상 모델 학습, 근사 정책 최적화를 통한 강화 학습 순으로 진행된다.
- Step 1) 데모 데이터를 수집하고 지도 정책으로 훈련한다
- 프롬프트 데이터 셋에서 프롬프트가 샘플링된다.
- 라벨러가 원하는 출력 동작을 보여준다.
- 이 데이터는 지도 학습을 통해 모델을 파인튜닝하는 데 사용된다.
- Step 2) 비교 데이터를 수집하고 보상 모델을 훈련한다.
- 샘플링된 프롬프트에 여러 라벨이 수집된다.
- 라벨러는 출력물의 순위를 최고부터 최하위까지 매긴다.
- 이 데이터는 보상 모델을 학습하는 데 사용된다.
- Step 3) 강화 학습을 사용해 보상 모델에 대한 정책을 최적화 한다.
- 데이터 셋에서 새 프롬프트가 샘플링된다.
- 정책에서 출력을 생성한다.
- 보상 모델은 산출물에 대한 보상을 계산한다.
- 보상은 PPO를 사용하여 정책을 업데이트하는 데 사용된다.
정리하자면, 사람이 데이터에 라벨(텍스트)을 붙인 데이터 셋을 수집해 훈련하고,
사람이 라벨(순위)을 지정한 비교 데이터 셋을 수집해 보상 모델을 훈련, 이 보상 모델을 보상 함수로 사용해 파인튜닝한다.
Self-Instruct
정의
- 최소한의 인간 라벨링 데이터로 지시를 따르는 능력을 유도하는 방법으로,
모델 자체의 명령 신호를 사용하여 사전 학습된 LM을 명령어로 튜닝하는 반자동 프로세스이다. Alpaca에 사용되었다 - 전체 프로세스는 반복적인 부트스트랩 알고리즘으로, 전체 생성을 안내하는 데 사용되는 수동으로 작성된 명령어의 제한된 시드 세트로 시작한다.
- 부트스트랩 : 비용과 시간이 많이 드는 데이터 수집을 스스로 해결할 수 있는 샘플링 방법이다.
절차
아래 그림은 Self-Instruct의 개요를 나타낸다.
- 명령어 데이터를 생성하는 파이프라인은 4단계로 구성된다.
1) 명령어 생성
2) 명령어가 분류 작업을 나타내는지 여부 식별
3) 입력 우선 또는 출력 우선 접근 방식을 사용한 인스턴스 생성
4) 품질이 낮은 데이터 필터링
먼저 모델에서 명령어를 생성하는 파이프라인을 사용하여 언어 모델에서 명령어, 입력 및 출력 샘플을 생성한 다음 해당 명령어를 사용하여 입력-출력 쌍을 생성한다.
생성된 명령어는 입력 생성을 안내하는 데 사용되며, 입력은 모델에 공급되어 출력을 생성한다.
그런 다음 이러한 입력-출력 쌍은 품질과 관련성에 따라 잘라낸 다음 원래 모델을 미세 조정하는 데 사용된다.
장점
- 모델 자체에서 고품질의 명령어, 입력 및 출력 샘플을 생성하기에 사람이 작성한 명령어 데이터에 대한 의존도를 줄일 수 있다.
- Self-Instruct를 사용하여 합성 데이터를 생성하면 모델을 파인튜닝하는 데 사용할 수 있는 학습 데이터의 다양성과 양을 늘릴 수 있다.
- 모델 자체의 세대를 기반으로 지침을 생성하기에 모델 자체의 언어 이해도와 지침을 따르는 능력을 파악할 수 있다.
즉, 튜닝된 모델은 더 일반화할 수 있고 학습 데이터에서 볼 수 있는 것 이상의 광범위한 작업에서 잘 수행할 수 있다.
ChatLlama라는 레포지토리의 구조를 통해 RLHF 코드 분석
강화학습을 위한 인간 피드백은 인간의 피드백을 통해 강화학습 모델을 학습시키는 방법입니다. 이 방법은 보상 모델(Reward Model)을 사용하여 강화학습 모델을 학습하고, 이 모델을 사용하여 Actor-Critic 모델을 훈련시킵니다.
PPO (Proximal Policy Optimization) 알고리즘은 강화 학습 알고리즘 중 하나로, 정책(Policy)과 가치(Value)를 함께 학습시키는 Actor-Critic 구조를 사용합니다.
Reward Model 클래스는 PyTorch 라이브러리를 사용하여 RL (Reinforcement Learning)에서 보상(Reward) 모델링을 위한 모델을 정의하고 학습시키는 데 사용됩니다.
이 클래스는 torch.nn.Module을 상속하며, 선택한 모델(GPT2, BART, Longformer 등 LLM보다 작은 모델)에 대한 tokenizer와 head를 설정하고, 모델의 매개변수를 고정하고 헤드만 학습하도록 설정합니다. forward 메서드는 입력 시퀀스와 마스크를 모델에 전달하여 출력 텐서(보상 값)를 반환하고, get_reward 메서드는 출력 시퀀스와 마스크를 입력으로 받고, forward 메서드를 사용하여 출력 텐서에서 마지막 값을 추출하여 보상으로 사용합니다.

Actor-Critic 모델은 두 개의 하위 모델인 Actor 모델과 Critic 모델로 구성됩니다. Actor 모델은 토큰 시퀀스(텍스트)를 생성하는 역할을 하며, Critic 모델은 생성된 시퀀스에 대한 가치를 예측하는 역할을 합니다.
ActorModel은 LLM이 되고, CriticModel은 이때 Reword Model과 같은 모델을 사용하게 됩니다. Reward Model은 사전에 학습이 되어야 하며, 이를 통해 예측된 보상 값을 사용하여 ActorModel에서 행동 결정을 합니다.
Reward Model과 Critic 모델이 같은 구조와 가중치를 가진 Reward Model과 Critic 모델은 동일한 모델을 사용할 수도 있습니다. 이 경우 Reward Model은 주어진 상태와 액션에 대한 예상 보상을 계산하고, Critic 모델은 주어진 상태의 가치를 예측합니다. 두 모델은 서로 다른 목적을 가지고 있으며, 학습 과정에서 각각의 모델은 다른 정보를 활용합니다.
Actor 모델은 Critic 모델로부터 얻은 가치 값과 Reward Model에서 얻은 보상 값을 모두 고려하여 최적의 행동을 선택하게 됩니다. 이를 위해 PPO 알고리즘을 사용하여 학습을 진행합니다. PPO 알고리즘은 policy loss와 value loss를 이용하여 학습을 진행합니다. policy loss는 새로운 액션의 액션 로그 확률을 이전 액션과 비교하여 계산되며, value loss는 새로운 가치 값과 이전 가치 값을 비교하여 계산됩니다. PPO 알고리즘은 PPO loss를 최소화하는 방향으로 학습을 진행합니다.
Actor 모델의 경우, surrogate loss와 KL divergence loss를 최소화합니다. surrogate loss는 현재 정책과 이전 정책 사이의 비율을 이용해 계산되는데, 이는 현재 정책이 이전 정책에 비해 더 나은 성능을 내도록 유도하기 위함입니다. KL divergence loss는 현재 정책이 이전 정책으로부터 멀어지지 않도록 유도하는 역할을 합니다.
Critic 모델의 경우, value loss 또는 critic loss를 최소화합니다. 이는 예측된 가치와 실제 가치(보상) 사이의 차이를 최소화하는 것을 목표로 합니다. 이를 위해 Advantage 함수가 사용됩니다. Advantage 함수는 현재 상태에서 예측된 가치와 이전 상태에서 예측된 가치 사이의 차이를 나타내는 값으로, Critic 모델이 더 나은 예측을 할 수 있도록 업데이트됩니다.
Reward 모델의 경우, 착각하기 쉬운게 Critic 모델하고 같은 모델을 사용하기 때문에 얼핏 Critic 모델이 업데이트 되면서 같이 업데이트 되는 것이 아닌가 착각할 수 있지만 Reward 모델은 고정되어서 계속 고정된 가중치로 주어진 상태 + 액션에 대한 예상 보상을 예측해준다. 그에 반해 Critic 모델은 같은 구조이지만 주어진 상태의 현재의 가치만 평가하고 계속되서 업데이트르 하기때문에 다르게 작동한다.

train.py 파일에서는 Actor-Critic 모델을 훈련하는데 사용되는 여러 함수가 정의되어 있습니다. generate 함수는 토큰 시퀀스를 생성하고, forward 함수는 액션 로짓과 가치를 계산합니다.
learn 함수는 메모리 데이터 세트를 사용하여 Actor-Critic 모델을 훈련합니다. 메모리에는 상태, 액션, 보상, 가치 및 시퀀스 정보가 저장됩니다. 데이터 로더를 생성하고 지정된 에포크 수 동안 Actor-Critic모델을 학습시킵니다.
각 에포크의 학습 루프는 데이터 로더의 배치를 반복하고, 각 시퀀스에 대해 액션 로그와 가치를 계산한 다음, PPO 손실을 계산하고 Critic 모델을 업데이트하는 과정으로 구성됩니다.
PPO 손실에는 정책 손실과 가치 손실이 포함되어 있으며, 이를 사용하여 정책 손실과 가치 손실을 계산합니다. 정책 손실은 새로운 액션의 액션 로그 확률을 이전 액션과 비교하여 계산되고, 가치 손실은 새로운 가치와 이전 가치 값을 비교하여 계산됩니다.
train 함수는 강화 학습 훈련의 설정과 매개 변수를 초기화하고, learn 함수를 사용하여 Actor-Critic모델을 훈련하고 저장합니다. 이렇게 훈련된 모델은 후속 태스크에서 사용될 수 있습니다.
요약하면, PPO 알고리즘을 기반으로 한 Actor-Critic 모델은 Reward Model을 사용하여 예상 보상을 계산하고, Critic 모델을 사용하여 상태의 가치를 예측합니다. Actor 모델은 Critic 모델과 Reward Model의 정보를 활용하여 최적의 행동을 선택합니다. 학습 과정에서는 PPO 손실을 최소화하는 방향으로 Actor 모델과 Critic 모델을 학습시킵니다.
StackLLaMA를 통해 분석하는 RLHF 코드 분석
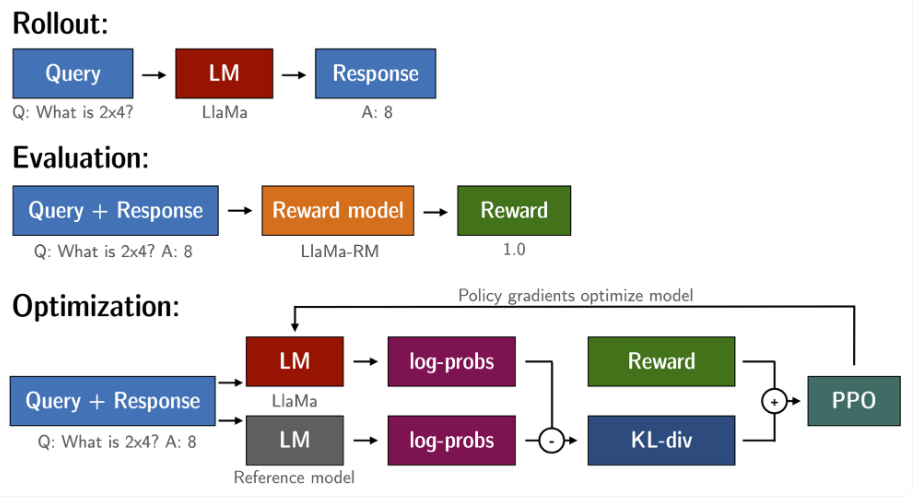
라이브러리는 TRL(Transformers Reinforce Learning)을 개발해서 사용한다.
trl는 Proximal Policy Optimization ( PPO )으로 변압기 언어 모델을 교육 할 수 있습니다. 따라서 사전 훈련 된 언어 모델을 허깅페이스의 transformers 라이브러리 통해 직접로드 할 수 있습니다
이 시점에서 대부분의 디코더 아키텍처 및 엔코더-디코더 아키텍처가 지원됩니다.
PPOTrainer: 언어 모델을 최적화하기 위해 ( 쿼리, 응답, 보상 ) 트리플세트가 필요한 언어 모델 용 PPO 트레이너.
AutoModelForCausalLMWithValueHead & AutoModelForSeq2SeqLMWithValueHead: 강화 학습에서 값 함수로 사용할 수있는 각 토큰에 대한 추가 스칼라 출력을 가진 트랜스포머 모델.
(예 : GPT2를 훈련시켜 BERT 감성 분류기로 긍정적인 영화 리뷰를 생성하십시오.)
작동 방식
PPO를 통한 언어 모델 미세 조정은 대략 3 단계로 구성됩니다:
롤아웃: 언어 모델은 문장의 시작이 될 수있는 쿼리를 기반으로 응답 또는 연속을 생성합니다.
평가: 쿼리 및 응답은 함수, 모델, 사람 피드백 또는 이들의 조합으로 평가됩니다. 중요한 것은이 프로세스가 각 쿼리 / 응답 쌍에 대한 스칼라 값을 산출해야한다는 것입니다.
최적화: 이것은 가장 복잡한 부분입니다. 최적화 단계에서 쿼리 / 응답 쌍은 시퀀스에서 토큰의 로그 확률을 계산하는 데 사용됩니다. 이것은 훈련 된 모델과 참조 모델로 이루어지며, 일반적으로 미세 조정 전에 사전 훈련 된 모델입니다. 두 출력 사이의 KL- 발산은 생성 된 응답이 참조 언어 모델에서 멀어지지 않도록 추가 보상 신호로 사용됩니다. 그런 다음 활성 언어 모델을 PPO로 교육합니다.
# imports
import torch
from transformers import AutoTokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model
from trl.core import respond_to_batch
# get models
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
model_ref = create_reference_model(model)
tokenizer = AutoTokenizer.from_pretrained('gpt2')
# initialize trainer
ppo_config = PPOConfig(
batch_size=1,
)
# encode a query
query_txt = "This morning I went to the "
query_tensor = tokenizer.encode(query_txt, return_tensors="pt")
# get model response
response_tensor = respond_to_batch(model, query_tensor)
# create a ppo trainer
ppo_trainer = PPOTrainer(ppo_config, model, model_ref, tokenizer)
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0)]
# train model for one step with ppo
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)참조자료
https://arxiv.org/abs/2203.02155
Training language models to follow instructions with human feedback
Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not ali
arxiv.org
https://arxiv.org/abs/2212.10560
https://github.com/juncongmoo/chatllama
GitHub - juncongmoo/chatllama: ChatLLaMA 📢 Open source implementation for LLaMA-based ChatGPT runnable in a single GPU. 15x f
ChatLLaMA 📢 Open source implementation for LLaMA-based ChatGPT runnable in a single GPU. 15x faster training process than ChatGPT - GitHub - juncongmoo/chatllama: ChatLLaMA 📢 Open source implementa...
github.com
https://huggingface.co/blog/stackllama
StackLLaMA: A hands-on guide to train LLaMA with RLHF
StackLLaMA: A hands-on guide to train LLaMA with RLHF Models such as ChatGPT, GPT-4, and Claude are powerful language models that have been fine-tuned using a method called Reinforcement Learning from Human Feedback (RLHF) to be better aligned with how we
huggingface.co
https://huggingface.co/blog/trl-peft
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU We are excited to officially release the integration of trl with peft to make Large Language Model (LLM) fine-tuning with Reinforcement Learning more accessible to anyone! In this post, we explain why t
huggingface.co
https://github.com/lvwerra/trl
GitHub - huggingface/trl: Train transformer language models with reinforcement learning.
Train transformer language models with reinforcement learning. - GitHub - huggingface/trl: Train transformer language models with reinforcement learning.
github.com
'코딩 > LLM' 카테고리의 다른 글
| 라마 인덱스와 랭체인 비교 (0) | 2023.11.01 |
|---|---|
| 벡터 데이터베이스와 벡터 인덱스 Faiss (1) | 2023.10.29 |
| LLaVA-1.5 이미지 텍스트 멀티모달 (1) | 2023.10.10 |
| 양자화 모델 실행과 LoRA 파인 튜닝 (1) | 2023.10.08 |
| AutoGPTQ를 이용한 양자화 하는 방법 (1) | 2023.10.07 |



